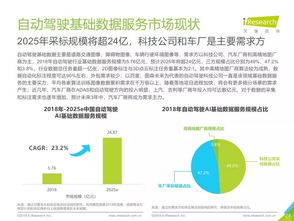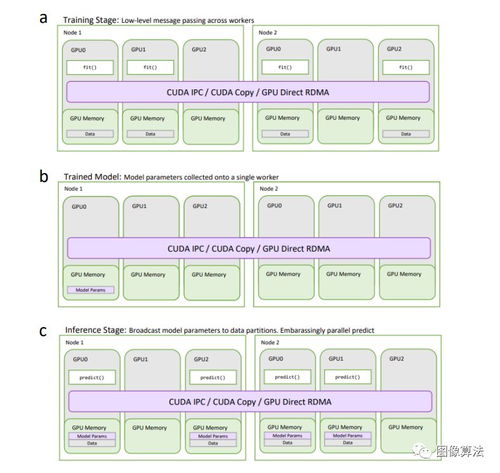
隨著人工智能技術(shù)的飛速發(fā)展,特別是在邊緣計(jì)算和物聯(lián)網(wǎng)場(chǎng)景下,對(duì)低功耗、高能效計(jì)算的需求日益迫切。傳統(tǒng)的馮·諾依曼架構(gòu)中,計(jì)算單元與存儲(chǔ)單元分離,頻繁的數(shù)據(jù)搬運(yùn)導(dǎo)致巨大的功耗開(kāi)銷(xiāo)和性能瓶頸,這已成為制約AI應(yīng)用廣泛部署的關(guān)鍵因素之一。在此背景下,基于SRAM的存內(nèi)計(jì)算作為一種顛覆性的計(jì)算范式應(yīng)運(yùn)而生,它通過(guò)在存儲(chǔ)器內(nèi)部直接執(zhí)行計(jì)算操作,從根本上避免了數(shù)據(jù)移動(dòng),為人工智能基礎(chǔ)軟件的開(kāi)發(fā)開(kāi)辟了全新路徑。
一、 SRAM存內(nèi)計(jì)算的基本原理與計(jì)算單元
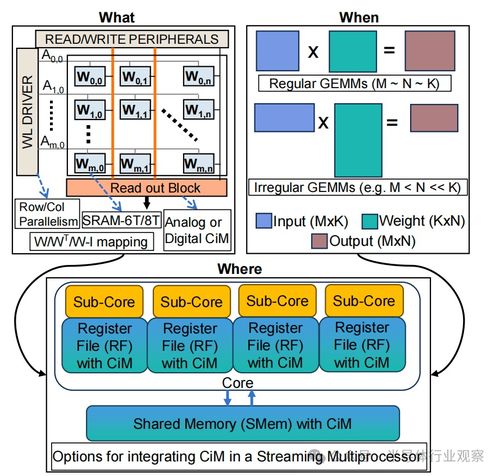
存內(nèi)計(jì)算的核心思想是“計(jì)算靠近數(shù)據(jù)”,乃至“在數(shù)據(jù)存儲(chǔ)的位置進(jìn)行計(jì)算”。靜態(tài)隨機(jī)存取存儲(chǔ)器因其存取速度快、結(jié)構(gòu)相對(duì)規(guī)整,成為實(shí)現(xiàn)存內(nèi)計(jì)算的理想載體之一。其基本計(jì)算單元通常基于SRAM存儲(chǔ)陣列本身。
- 模擬計(jì)算范式:主流的SRAM存內(nèi)計(jì)算方案多采用模擬信號(hào)處理的方式。在一個(gè)典型的SRAM陣列中,字線用于選擇行,位線用于讀取或?qū)懭霐?shù)據(jù)。在進(jìn)行計(jì)算時(shí),可以將輸入數(shù)據(jù)(例如神經(jīng)網(wǎng)絡(luò)的權(quán)重)預(yù)先編程到SRAM單元中(通過(guò)改變晶體管閾值或存儲(chǔ)電荷來(lái)表征不同的權(quán)重值),然后將另一組輸入數(shù)據(jù)(例如神經(jīng)網(wǎng)絡(luò)的激活值)以電壓或電流的形式施加到位線上。通過(guò)利用基爾霍夫定律或電荷共享原理,位線上的總電流或電壓的模擬量就代表了多組輸入與權(quán)重的乘加運(yùn)算結(jié)果。一個(gè)SRAM陣列可以并行完成大量(例如128x128)的乘累加操作,這正是深度學(xué)習(xí)卷積、全連接等核心運(yùn)算的本質(zhì)。
- 數(shù)字計(jì)算范式:也有研究探索基于SRAM的數(shù)字存內(nèi)計(jì)算,例如利用SRAM單元構(gòu)成查找表或直接進(jìn)行布爾邏輯運(yùn)算。雖然精度和靈活性可能更高,但在能效和并行度上通常不如模擬方式突出。
這種將存儲(chǔ)單元直接轉(zhuǎn)化為計(jì)算單元的設(shè)計(jì),使得SRAM陣列不再僅僅是數(shù)據(jù)的“倉(cāng)庫(kù)”,更成為了一個(gè)強(qiáng)大的“模擬計(jì)算引擎”。
二、 對(duì)人工智能基礎(chǔ)軟件開(kāi)發(fā)的深刻影響
SRAM存內(nèi)計(jì)算硬件架構(gòu)的特殊性,對(duì)上層的人工智能基礎(chǔ)軟件棧(包括編譯器、編程模型、框架、運(yùn)行時(shí)等)提出了全新的要求和挑戰(zhàn),同時(shí)也帶來(lái)了巨大的機(jī)遇。
- 軟件棧的重新定義:傳統(tǒng)的AI軟件棧(如基于CUDA的PyTorch/TensorFlow)是針對(duì)GPU等通用處理器設(shè)計(jì)的,其核心是調(diào)度計(jì)算核心處理從內(nèi)存加載的數(shù)據(jù)。而對(duì)于存內(nèi)計(jì)算處理器,軟件棧需要管理的是“在存儲(chǔ)器中的計(jì)算”。這需要全新的編程抽象和編程模型。開(kāi)發(fā)者可能需要一種新的語(yǔ)言或擴(kuò)展來(lái)描述如何在存儲(chǔ)陣列中映射數(shù)據(jù)和計(jì)算任務(wù),而不是編寫(xiě)顯式的乘加循環(huán)。
- 編譯器的關(guān)鍵角色:編譯器成為連接算法模型與存內(nèi)計(jì)算硬件的核心橋梁。一個(gè)先進(jìn)的存內(nèi)計(jì)算編譯器需要完成以下關(guān)鍵任務(wù):
- 算法映射與優(yōu)化:將神經(jīng)網(wǎng)絡(luò)的層(如卷積、全連接)高效地分解和映射到物理的SRAM計(jì)算陣列上,考慮陣列的規(guī)模、精度和模擬域特性。
- 數(shù)據(jù)流與調(diào)度:優(yōu)化輸入數(shù)據(jù)、中間結(jié)果在多個(gè)存內(nèi)計(jì)算陣列之間以及與傳統(tǒng)處理單元(如CPU)之間的流動(dòng),以隱藏?cái)?shù)據(jù)轉(zhuǎn)換(如模數(shù)轉(zhuǎn)換)的延遲。
- 精度與噪聲管理:模擬計(jì)算易受噪聲、工藝偏差和溫度影響。編譯器需要與硬件校準(zhǔn)信息結(jié)合,可能需要在軟件層面集成誤差補(bǔ)償、剪枝或重訓(xùn)練算法,以確保最終的推理精度。
- 框架集成與工具鏈:為了降低開(kāi)發(fā)門(mén)檻,主流的AI框架(如TensorFlow、PyTorch)需要提供對(duì)存內(nèi)計(jì)算硬件的后端支持。這可能以插件或定制化操作符的形式出現(xiàn)。完整的工具鏈應(yīng)包括模擬器、性能/功耗分析器、調(diào)試工具等,允許軟件開(kāi)發(fā)者在將模型部署到真實(shí)芯片之前,就能評(píng)估其在存內(nèi)計(jì)算架構(gòu)上的行為和效能。
- 驅(qū)動(dòng)新型算法研究:存內(nèi)計(jì)算硬件的特點(diǎn)(如高并行模擬計(jì)算、有限精度)也在反過(guò)來(lái)推動(dòng)AI算法的創(chuàng)新。例如,促進(jìn)對(duì)量化訓(xùn)練、稀疏化、二值/三值網(wǎng)絡(luò)等硬件友好型算法的深入研究,以充分發(fā)揮存內(nèi)計(jì)算的能效優(yōu)勢(shì)。
三、 挑戰(zhàn)與未來(lái)展望
盡管前景廣闊,基于SRAM的存內(nèi)計(jì)算及其軟件開(kāi)發(fā)仍面臨挑戰(zhàn):模擬計(jì)算的精度與動(dòng)態(tài)范圍限制、工藝偏差的補(bǔ)償、多陣列協(xié)同計(jì)算的編程復(fù)雜度、以及與傳統(tǒng)計(jì)算生態(tài)的融合等。
基于SRAM的存內(nèi)計(jì)算有望率先在智能傳感器、可穿戴設(shè)備、手機(jī)等邊緣AI場(chǎng)景實(shí)現(xiàn)商業(yè)化落地。其基礎(chǔ)軟件的成熟將是引爆點(diǎn)。一個(gè)理想的愿景是:AI開(kāi)發(fā)者只需關(guān)注算法邏輯,而一個(gè)高度智能的軟件棧能夠自動(dòng)將其高效、低功耗地部署在存內(nèi)計(jì)算硬件上。這需要硬件架構(gòu)師、電路設(shè)計(jì)師、編譯器專(zhuān)家和AI軟件工程師的深度協(xié)同創(chuàng)新。
基于SRAM的存內(nèi)計(jì)算不僅僅是硬件電路的革新,更是一場(chǎng)從硬件到軟件的全面計(jì)算范式變革。它正推動(dòng)人工智能基礎(chǔ)軟件開(kāi)發(fā)從“以計(jì)算為中心”向“以數(shù)據(jù)為中心”演進(jìn)。隨著軟件工具的不斷完善和生態(tài)的逐步建立,存內(nèi)計(jì)算有望成為驅(qū)動(dòng)下一代邊緣智能乃至更廣泛AI應(yīng)用的基石性技術(shù),讓智能無(wú)處不在且能效卓越。