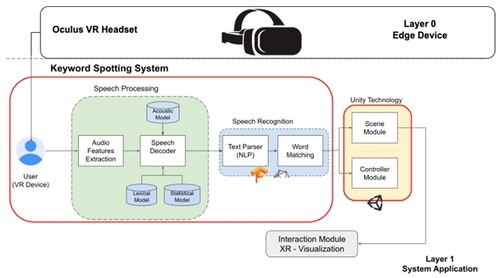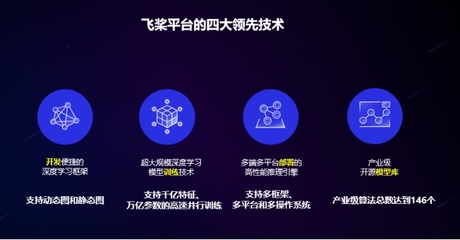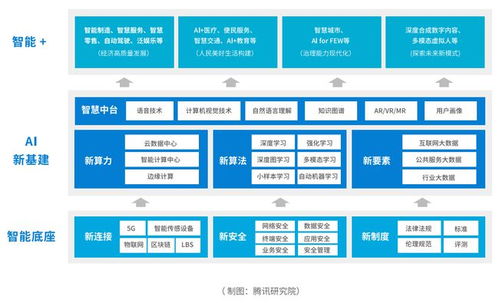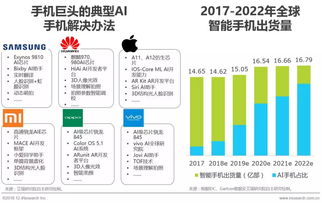
在當今技術浪潮中,Python、數據科學、機器學習和人工智能已成為推動創新的核心力量。這些領域相互交織,共同塑造著我們的未來。本文將概述其主要發展技術趨勢,并聚焦于人工智能基礎軟件開發的關鍵動態。
一、 Python:數據科學與AI的通用語言
Python憑借其簡潔語法、豐富的庫生態系統和強大的社區支持,穩坐數據科學和機器學習領域的頭把交椅。其趨勢體現在:
- 庫與框架的持續進化:NumPy、Pandas、Matplotlib等數據處理與可視化庫不斷優化;Scikit-learn作為經典機器學習庫保持活力;而深度學習框架如TensorFlow和PyTorch則持續角逐,推動模型開發效率與靈活性的邊界。
- Jupyter生態的擴展:Jupyter Notebook/Lab已成為交互式計算和協作研究的事實標準,并向更企業級、可復現的工作流演進。
- 性能與部署優化:通過Cython、Numba、PyPy等工具提升性能,并借助FastAPI、Streamlit等框架簡化模型部署與Web應用開發。
二、 數據科學:從洞察到自動化決策
數據科學已超越傳統統計分析,邁向更自動化、可操作的智能階段。
- 自動化機器學習(AutoML):工具如H2O.ai、TPOT、Auto-sklearn正降低機器學習應用門檻,自動化特征工程、模型選擇和超參數調優。
- 數據治理與可觀察性:隨著數據規模與復雜度激增,對數據質量、血緣追蹤和模型監控(MLOps的一部分)的需求日益迫切。
- 增強分析與數據編織:將機器學習深度嵌入分析流程,實現更智能的數據洞察與預測;數據編織架構旨在實現跨平臺數據的無縫集成與管理。
三、 機器學習:向更高效、更通用的模型演進
機器學習技術正沿著幾個關鍵方向快速發展:
- 大規模預訓練模型:以GPT、BERT、CLIP等為代表的Transformer架構模型,在自然語言處理、計算機視覺等多模態任務中展現出強大的泛化與遷移能力,催生了“基礎模型”范式。
- 高效與輕量化學習:聯邦學習、差分隱私技術在保護數據隱私的同時進行模型訓練;知識蒸餾、模型剪枝、量化等技術致力于壓縮模型規模,以適配邊緣設備。
- 因果機器學習:超越相關性的模式識別,探索變量間的因果關系,為更可靠的科學發現與決策提供支持。
四、 人工智能:邁向更廣闊的應用與更深刻的融合
人工智能的發展已滲透至各行各業,其技術趨勢凸顯了廣度與深度的結合。
- 生成式AI的爆發:以DALL-E、Stable Diffusion、ChatGPT為代表的生成模型,在內容創作(文本、圖像、代碼、音視頻)領域引發革命,推動AIGC(AI Generated Content)成為熱點。
- 具身AI與機器人學:AI與物理世界交互的能力受到重視,推動機器人技術在感知、規劃與控制方面的進步。
- AI for Science:人工智能被廣泛應用于加速科學研究,如蛋白質結構預測(AlphaFold)、新材料發現、氣候建模等領域。
五、 人工智能基礎軟件開發:構建智能時代的基石
支撐上述應用的是快速演進的人工智能基礎軟件棧,其核心關注點包括:
- 開發框架與工具鏈:
- TensorFlow / PyTorch:兩大主流深度學習框架,持續在易用性、性能(編譯優化、分布式訓練)和部署(TF Serving, TorchServe)上競爭與創新。
- 統一與高層API:如Keras、PyTorch Lightning、Fast.ai,旨在簡化模型構建與訓練流程,提升開發效率。
- 專用硬件支持:框架深度集成GPU(NVIDIA CUDA)、TPU以及新興的AI芯片,以充分利用算力。
- MLOps平臺與生命周期管理:
- 端到端平臺:如MLflow、Kubeflow、Azure ML、Amazon SageMaker,提供從實驗跟蹤、管道編排到模型部署、監控的全套工具,以實現機器學習的標準化和規模化。
- 模型部署與服務化:ONNX格式促進框架間模型交換;Triton Inference Server等提供高性能推理服務。
- 開源生態與社區驅動:
- 強大的開源社區(如Hugging Face的Transformers庫)極大地加速了最新模型的傳播與應用。
- 開源基礎模型(如BLOOM、Stable Diffusion)的發布,降低了前沿AI技術的獲取門檻。
****
Python作為粘合劑,將數據科學、機器學習與人工智能緊密連接。技術發展將更加注重模型的效率、可解釋性、公平性及與物理世界的安全交互。強大、靈活且易用的基礎軟件開發平臺和工具鏈,是釋放人工智能全部潛力的關鍵,它們正朝著更自動化、更一體化、更面向生產的方向飛速演進。開發者與研究者需要持續關注這些趨勢,以把握智能時代的技術脈搏。